
So you are building an AI assistant for the business?
This is a popular topic in the companies these days. Everybody seems to be doing that.
While running AI Research in the last months, I have discovered that many companies in the USA and Europe are building some sort of AI assistants these days, mostly around enterprise workflow automation and knowledge bases.
There are common patterns in how such projects work most of the time. So let me tell you a story. This could help us to avoid possible known pitfalls, save some time and ship the product faster.
Building an AI assistant
AI assistant project at a company usually starts with an idea: “Let’s build a business assistant or copilot to solve a problem X”. Problems are usually the ones that require:
-
Answering questions based on the corporate knowledge bases
-
Understanding tables in business reports
-
Being able to run marketing research on the Internet
-
Working locally with sensitive data (e.g. banking, insurance or anything that goes into the data rooms)
Based on the internet research, engineering teams decide that current AI technology is mature enough. Surely, there are enough good success stories.
They pick a tool like:
-
LangChain - “Applications that can reason. Powered by LangChain… From startups to global enterprises, ambitious builders choose LangChain.”
-
LlamaIndex - “Turn your enterprise data into production-ready LLM applications”
-
QDrant - “powering thousands of innovative AI solutions at leading companies”
There is even an official NVIDIA project Chat with RTX that lets us upload our documents and start chatting with an assistant.
These are fun times that go by fast. Teams pick their tools and start working steadily, exchanging new terms and discoveries: vector databases, agents, text chunking and computing embeddings, function calling, tools and Chains of Thought.
First results of the assistant are really good - it is capable of providing knowledgeable and insightful answers in most of the cases. This proves that the prototype is good enough to go for a proper development and deployment.
A few months down the road, the system is deployed. It still works good in most of the cases. But that’s where people start realising that something is not quite right.
You see, the system sometimes also hallucinates. It used to hallucinate a bit during the testing, but after the deployment to the real users, things get a bit more worse.
You see, more specific the question is, higher is the chance that the answer be a nonsense. For some reason the specific questions were not asked before, not until the end users started playing with the system.
End users will be asking very specific questions about their daily jobs, questions they already know answer for. Some people would be even willing to go at great lengths to prove that AI doesn’t work at all. Fear of loosing jobs to AI has always been an important factor.
Hallucinations and mistakes in AI are never a good thing. What is the point of using a system that you can’t trust?
Fortunately, public resources provide many ways to improve the accuracy of a mis-behaving AI assistant.
-
Better prompting
-
Tweaking retrieval and fine-tuning embeddings
-
Query transformations (expansion)
-
Chunk reranking
-
Adding multiple agents and building routers
In the end architecture of an AI assistant could grow as complex as the one below. Yet, the it still will not be able to always answer simple questions. It will lack the accuracy and hallucinate from time to time.
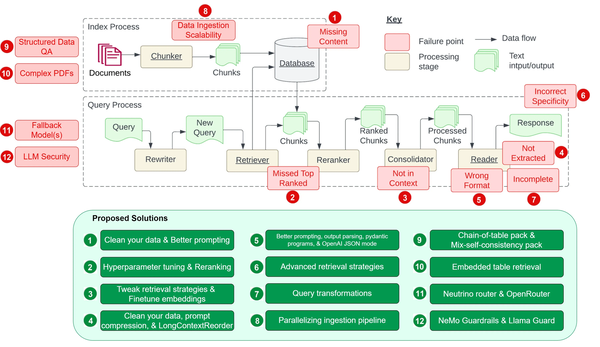
IMAGE FROM: HTTPS://TOWARDSDATASCIENCE.COM/12-RAG-PAIN-POINTS-AND-PROPOSED-SOLUTIONS-43709939A28C
So what should the teams do at this point? So much effort already invested, and the accuracy is almost there. We probably just need to fine-tune a proper LLM and everything will be finally working.
At this point, I’m not willing to continue going further into this rabbit hole, even in telling a story. There ending is not happy there.
Been there, done that. Also have seen many companies follow this path.
Fortunately, this is just a story. So we can ask the question “What went wrong?”, then rewind the time a few months back and do things differently.
What went wrong and at which point?
Things went wrong at the very start. There are 3 assumptions that are commonly misjudged.
-
Public materials and articles tell the whole truth about how state-of-the-art AI systems actually work in business.
-
If we shred our documents into small chunks, then put them into a vector database, then AI will be able to magically make sense out of that.
-
We need to build an omnipotent AI assistant with complex architecture, in order to bring value to a business.
In my experience, all of these are wrong. The assumptions may be useful, if we want to mislead our competitition into going into a deep rabbit hole. But ultimately they are wrong.
We can significantly reduce the risk by testing and verifying these assumptions before committing to a bit project. Also by:
-
talking to the end users first;
-
asking questions and gathering data beforehand;
-
designing a system that is built to capture feedback and learn even after the first deployment.
Story with a happy ending
Here is one common and repeated path to a successfully deployed AI assistant:
-
Start by asking the questions about the business. Identify process steps that could potentially be automated, based on the existing success stories. Prioritise cases that represent the “lowest hanging fruit”
-
Talk to the process stakeholders, gain insights about how things really work. Look for the specific repeatable patterns. ChatGPT/LLMs are good at working with patterns.
-
Establish a quality metric, before writing a single line of code. For example, come up with a list of 40 questions that the system should be able to answer correctly. Identify these correct answers beforehand. This will be our first evaluation dataset.
-
Give a list of 20 questions with answers to the developers and ask them to build a prototype. Don’t ask for a fancy UI at this point, this will be just a waste of time. This can be a Jupyter notebook with Gradio interface that the team can show over a screen share.
-
Ideally, developers will just cluster the questions together into categories. Then they will figure out a pipeline that prepares documents in such a way, that a ChatGPT prompt for this question category will be able to produce a correct answer.
-
Once developers are satisfied with the quality, test the system prototype on the remaining 20 questions. This will be a wake-up call for many. Count the number of mistakes.
-
Now give developers a little bit of time and let them adjust the system so that it can handle these 20 questions. Measure the time it took to adjust the system.
-
Give developers 20 more questions they haven’t seen. Measure the time it takes them to fix them now, also count the number of mistakes after the iteration.
Repeat the last step a couple of times, still without investing into the complex UI and user experience (since these will just slow us down).
At this point we should have a trend: with each new iteration, the number of correctly answered questions increases, while the time it takes to make the system “learn” about that - stays the same or even decreases.
If numbers don’t follow the trend (a frequent case with RAG systems based on vector databases), then it is time to close the prototype.
If the trend persists - then we can continue it into the future - build a better user experience, deploy it to the end users, but tell the users this:
The system is designed to be learning over the time. So it is very important for us if you would rate answers of the system, when they are correct or incorrect. We will incorporate feedback back into the underlying architecture in a semi-automatic way. This way with each passing iteration the system will understand the specifics of your business much better.
Under the hood, your teams will continue following the same pattern they have done in the past:
-
Take new rated questions and add them to the evaluation dataset.
-
Figure out why doesn’t the AI Assistant handle the questions properly. Restructure prompts and data preparation until overall quality increases.
-
Test new versions against the entire evaluation dataset. If things look good, deploy it to the end users to gather more data and edge cases.
-
Repeat.
Sometime within this process, the teams might gather so much feedback, that they can experiment with fine-tuning models or even training ones. At this point, this will just be a controlled experiment - “Can we make the AI assistant better by training a custom model?”
If the numbers tell otherwise, we can get back to the original old-school process that actually works.
Summary
There is a lot of hype around AI and AI assistants these days. This hype is partially fuelled by the companies that sell shovels in this gold rush. All solution providers are partially incentivised to keep around problems to which they provide solutions.
This situation can waste time and energy.
You can save time and sometimes even ship products with AI/GPT faster, if you:
-
Treat everything with a grain of salt, including this blog post.
-
Learn about the mistakes and successes of the others before starting projects.
-
Start by gathering evaluation datasets from the end-users of the actual AI-systems.
-
Use customer feedback to measure quality of AI system from day one. Use it to drive the development.
-
Abort and reconsider the project, if the quality doesn’t improve over the time.
Image examples, so we get an idea how we should design the artwork for the blog post:
You can search for images on Google and copy them here, or add a self made sketch. We will then take it and create new shiny versions from it.



















